|
Cours B3 n° 16472 1999/2000 DATALOG - SQL |
Bases de données relationnelles
et
déductives (?)

Tuples et attributs
Soient d1
un tuple < d1 , ... , dn>
-
Cardinalité d'une relation : nombre de tuples de R (pas
d'ordre)
-
Table : une relation peut être représentée
par une table
-
Attribut : les noms des colonnes (ou n° de colonne) de
la table sont les attributs de la relation
- Schéma d'une relation : la liste ordonnée des attributsSchéma d'une relation : la liste ordonnée des attributs.
![]()
![]()
Base de données
Soient les relations
enseigne et
suit :
|
|
![]()
![]()
en DATALOG on écrira :
enseigne(milton, cs507).
enseigne(milton, cs531).
enseigne(kim, cs502).
enseigne(barth, cs501).
enseigne(gupta, cs523).
suit(adams, cs507, a).
suit(adams, cs502, b).
suit(arnold, cs507, a).
suit(arnold, cs531, c).
suit(arnold, cs501, a).
suit(alt, cs507, a).
% données extensionnelles
% remarquer les minuscules car les données sont des
constantes
![]()
![]()
Requêtes SQL et buts DATALOG
Sélection : réduction du nombre des lignes
| SQL | SELECT * FROM enseigne WHERE Enseignant = milton |
||||
| Résultats : |
|
| DATALOG | ?- enseigne(milton,Cours). |
| Résultats : | Cours = cs507
;
Cours = cs531 ; no |
![]()
![]()
Projection : réduction du nombre des colonnes
|
% remarquer l'utilisation d'une variable anonyme... |
![]()
![]()
Union, intersection et différence
(entre relations ayant les mêmes attributs)
2 nouvelles relations :
|
|
![]()
![]()
UNION (entre relations ayant les mêmes attributs)
| SQL | SELECT * FROM demande UNION SELECT * FROM autorisation |
||||||||||||||||
| Résultats |
|
![]()
![]()
| DATALOG | union(Etudiant, Cours):-
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Résultats |
|
![]()
![]()
Intersection (entre relations ayant les mêmes attributs)
| SQL | SELECT * FROM demande WHERE EXISTS ( SELECT * FROM autorisation WHERE demande.étudiant = autorisation.étudiant AND demande.cours = autorisation.cours ) |
||||||
| Résultats |
|
![]()
![]()
| DATALOG | intersection(Etudiant,Cours):- demande(Etudiant,Cours), autorisation(Etudiant,Cours). ?- intersection(Etudiant,Cours). |
|||||||||||||||||||||||||||||||||||
| Résultats |
|
![]()
![]()
Jointure (entre relations ayant des attributs communs)
| SQL : | SELECT enseigne.Enseignant, suit.Etudiant,
suit.Cours, suit.Niveau FROM enseigne, suit WHERE enseigne.Cours = suit.Cours ; |
||||||||||||||||||||||||||||
| Résultats |
|
![]()
![]()
| DATALOG | jointure(Enseignant,Etudiant,Cours,Niveau):- enseigne(Enseignant,Cours), suit(Etudiant,Cours,Niveau). ?- jointure(En,Et,C,N) |
|||||||||||||||||||||||||||||||||||
| Résultats |
|
![]()
![]()
Algèbre relationnelle
Définitions :
Algèbre (structure algèbrique) : ensemble(s) muni(s) de fonctions et relations
Opérateur (sur les ensembles) : fonction d'une relation dans une autre.
ex : la composition de relation R1°R2
Algèbre relationnelle : ensemble des relations muni des opérateurs de sélection , projection , produit cartésien ,
union , différence , jointure (opérateur dérivé)
![]()
![]()
Notations
(algèbre relationnelle)
Soit F une formule entre attributs de relations (+ constantes)
Sélection :
![]() F
R :
F
R : ![]() enseignant=milton enseigne
enseignant=milton enseigne
Projection : R d'arité n , i1,..., ik des noms d'attributs ou des numéros de colonnes o<k <= n,
![]() i1,..., ikR
la relation d'arité k et d'attributs i1,..., ik
obtenus à partir de R par suppression des autres colonnes
i1,..., ikR
la relation d'arité k et d'attributs i1,..., ik
obtenus à partir de R par suppression des autres colonnes
(la cardinalité peut donc en être différente).
ex :
![]() cours,niveau
suit
cours,niveau
suit
Produit cartésien : R x S ( d'arité a(R) + a(S) )
Le schéma de R x S est obtenu par concaténation de ceux de R et S
Union de deux relations de même schéma
différence : R-S ex: demande - autorisation
L'ensemble des 5 opérateurs est complet
(même pouvoir d'expression que le calcul de prédicats)
![]()
![]()
opérateurs
dérivés
Jointure : F une formule réduite à la comparaison d'attributs des 2 relations opérandes
R |><| F S =
![]() F
(R x S)
F
(R x S)
Jointure naturelle : R |><| S
Toute paire d'attributs de même nom est supposée sous contrainte d'égalité
Semi-jointure : R |>< F S =
![]() Schéma(R)
(R |><| S)
Schéma(R)
(R |><| S)
![]()
![]()
SQL / DATALOG / Algèbre relationnelle
3 relations R1,R2,R3 :
R1(A1,A2,A3) , R2(A4,A5,A6) , R3(A7,A8,A9)
SQL
SELECT R1.A1, R3.A9
FROM R1,R2,R3
WHERE R1.A2 = a
AND R2.A5 = b
AND R3.A8 = c
AND R1.A3 =
R2.A4
AND R2.A6 = R3.A7
;
![]()
![]()
DATALOG
but(A1,A9) :-
r1(A1,a,A3),
r2(A4,A5,A6), A5=b , A4=A3
r3(A7,A8,A9), A8=c , A7=A6.
%ou bien ("plus Prolog...")
but1(A1,A9):-
r1(A1 , a , X),
r2(X , b , Y),
r3(Y , c , A9).
![]()
![]()
Algèbre relationnelle
![]() A1,A9
((
A1,A9
((![]() A2=aR1)
|><|A3=A4
(
A2=aR1)
|><|A3=A4
(![]() A5=b
R2))
A5=b
R2))
|><|A6=A7
(![]() A8=cR3)
A8=cR3)
![]()
![]()
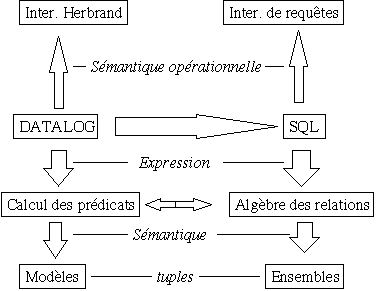
![]()
![]()
La comparaison, le parallèle ne s'arrête pas là, on verra qu'on dispose en Prolog d'outils pour représenter les contrainte d'intégrité, pour la mise à jour, pour construire des vues SQL, etc...
Tableau de correspondance :
| Base de données | DATALOG-Prolog | |
|---|---|---|
| Relation |
|
Prédicat |
| Attribut | <--> |
Argument |
| Tuple | <--> |
Fait clos |
| Vue | <--> |
Règle |
| Requête | <--> |
But |
| Contrainte | <--> |
But |
![]()
![]()
Idée : implantation de la fonction Tp et
itération de celle-ci dans l'algèbre relationnelle
Deux phases :
1. Calcul des relations en cause.
2. Extraction des faits/Tuples relatifs à la question .
Exemple en DATALOG on peut poser la question
?- ancêtre(paul,Y).
Elle correspond à la relation Ancêtre :
| Ancêtre = | Parent | U | |
| 1ère clause | 2ème clause |
Chercher le plus petit point fixe de cette équation récursive ou encore, la plus petite relation Ancêtre qui satisfasse cette équation.
![]()
![]()
Etape O : ancêtre0 =
ø
Etape 1 : ancêtre1 = parent U
![]() 1,4(
1,4(![]() 2=3(parent
x ancêtre0))
2=3(parent
x ancêtre0))
=
parent
Etape 2 : ancêtre2 = parent U
![]() 1,4(
1,4(![]() 2=3(parent
x ancêtre1))
2=3(parent
x ancêtre1))
= parent
U
![]() 1,4(
1,4(![]() 2=3(parent
x parent))
2=3(parent
x parent))
Etape 3 : ancêtre3 = parent U
![]() 1,4(
1,4(![]() 2=3(parent
x ancêtre2))
2=3(parent
x ancêtre2))
= parent
U
![]() 1,4(
1,4(![]() 2=3(parent
x parent)) U
2=3(parent
x parent)) U
![]() 1,6(
1,6(![]() 2=3,4=5(parent
x parent x parent ))
2=3,4=5(parent
x parent x parent ))
=
ancêtre2 U
![]() 1,6(
1,6(![]() 2=3,4=5(parent
x parent x parent ))
2=3,4=5(parent
x parent x parent ))
Etape 4 ...